Abir Harrasseعبير الهراس
/ʕæˈbiːr hɑˈrɑːs/
Hello! I'm a PhD student at ETH Zurich (D-INFK), working on mechanistic interpretability, LLM reasoning, and reliable deep learning. I'm drawn to understanding intelligence through deep neural networks - how they work, when they generalize, and how to make them reliable.
I'm advised by Prof. Mrinmaya Sachan and Prof. Bjoern Menze, and generously supported by the ETH AI Center Doctoral Fellowship. Before ETH, I was a Research Scientist at Martian Learning Inc., where I worked on mechanistic interpretability and LLM routing.
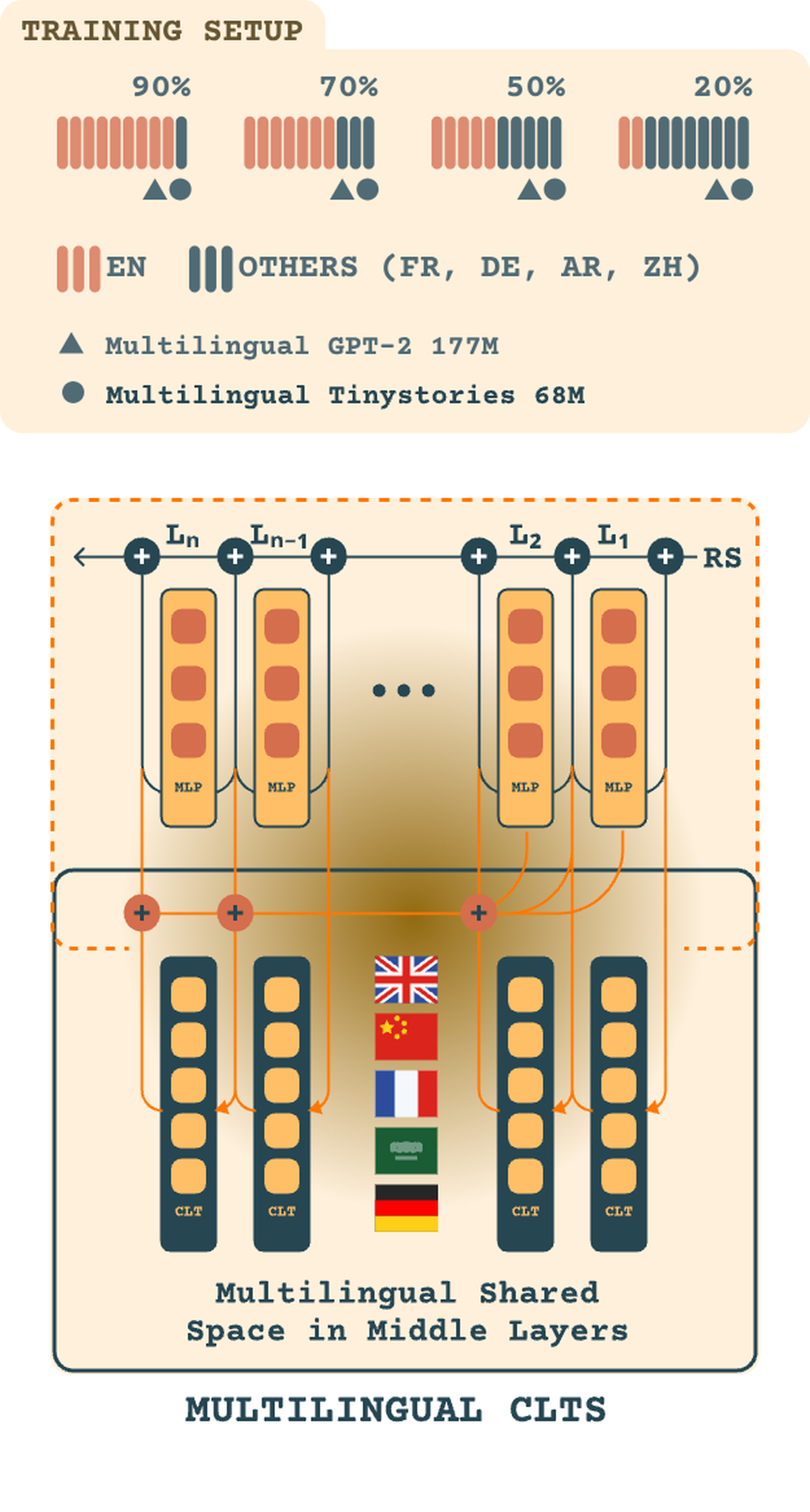
Before that, I was a research intern at MPI-IS Tübingen under Zhijing Jin and Bernhard Schölkopf, where I worked on understanding multilingual representations in LLMs using cross-layer transcoders. I also completed my Diplôme d'Ingénieur at EMINES (selected as best thesis, first-class honors), and interned at NUS where I developed novel evaluation frameworks for LLMs inspired by social choice and economic theory.
I'm proudly Moroccan. I've grown up across different parts of Morocco - Marrakech, then Elhajeb, Benguerir during my studies at EMINES, and now Tangier - each place leaving its mark on how I see the world. I love reading and am trying to rekindle the habit. I also write (mostly in French), sing in my spare time, and recently started learning photography, inspired by my father's wonderful tradition of making photo albums for us. I enjoy philosophizing about the world, whether alone or with my sister.
Research Interests
- Problem solving and reasoning in AI
- AI for scientific discovery and mathematics
- Generalization and robustness in neural networks
- Interpretability of deep neural networks